Cloudprober explicado: como lo usamos en Hostinger

Cloudprober es un software que se utiliza para monitorear la disponibilidad y el rendimiento de varios componentes del sistema. Aquí en Hostinger, lo usamos para monitorear el tiempo de carga de los sitios web de nuestros clientes. Inicialmente, comenzó como la aplicación gratuita de código abierto de Google, que se inició para ayudar a los clientes a monitorear sus proyectos o infraestructuras.
La tarea principal de Cloudprober es ejecutar sondeos, que están destinados a sondear protocolos como HTTP, Ping, UDP, DNS para verificar que los sistemas funcionen como se espera desde el punto de vista de los clientes. Incluso es posible tener una sonda personalizada específica (por ejemplo, Redis o MySQL) a través de una API de sonda externa. Hostinger se centra en la sonda HTTP.
Configuración de la sonda
Cada sonda se define como la combinación de estos ajustes particulares:
- Tipo: por ejemplo, HTTP, PING o UDP.
- Nombre: cada sonda debe tener un nombre único.
- Interval_msec: describe la frecuencia con la que se ejecuta la sonda (en milisegundos).
- Timeout_msec: tiempo de espera de la sonda (en milisegundos)
- Objetivos: objetivos contra los que ejecutar la sonda.
- Validador: validadores de sonda.
- <type>_probe: la configuración específica del tipo de sonda.
Surfacers
Los Surfacers son mecanismos integrados diseñados para exportar datos a múltiples sistemas de monitoreo. Se pueden configurar varios Surfacers al mismo tiempo. Cloudprober tiene como objetivo principal ejecutar sondeos y crear métricas utilizables estándar basadas en los resultados de esos sondeos. Por lo tanto, proporciona una interfaz fácil de usar que hace que los datos de la sonda estén disponibles para los sistemas que ofrecen formas de consumir datos de monitoreo.
Actualmente, Cloudprober admite los siguientes tipos de aparejos: Stackdriver (Google Cloud Monitoring), Prometheus, Cloudwatch (AWS Cloud Monitoring), Google Pub / Sub, File y Postgres.
Validadores
Los validadores de Cloudprober permiten ejecutar comprobaciones en las salidas de la solicitud de la sonda, si las hay. Se puede configurar más de un validador, pero todos deben tener éxito para que la sonda se marque como exitosa.
El validador Regex es el más común y funciona para la mayoría de los tipos de sonda. Cuando carga el sitio y espera que haya una cadena dentro, el Validador de expresiones regulares lo ayuda a hacerlo dinámico.
El validador HTTP, que solo es aplicable para un tipo de sonda HTTP, ayuda a verificar el encabezado (éxito/error) y el código de estado (éxito/error).
Por último, el validador de integridad de datos se utiliza principalmente para UDP o PINGS cuando esperamos datos en algún patrón repetitivo (por ejemplo, 1,2,3,1,2,3,1,2,3 en la carga útil).
Descubrimiento de objetivos
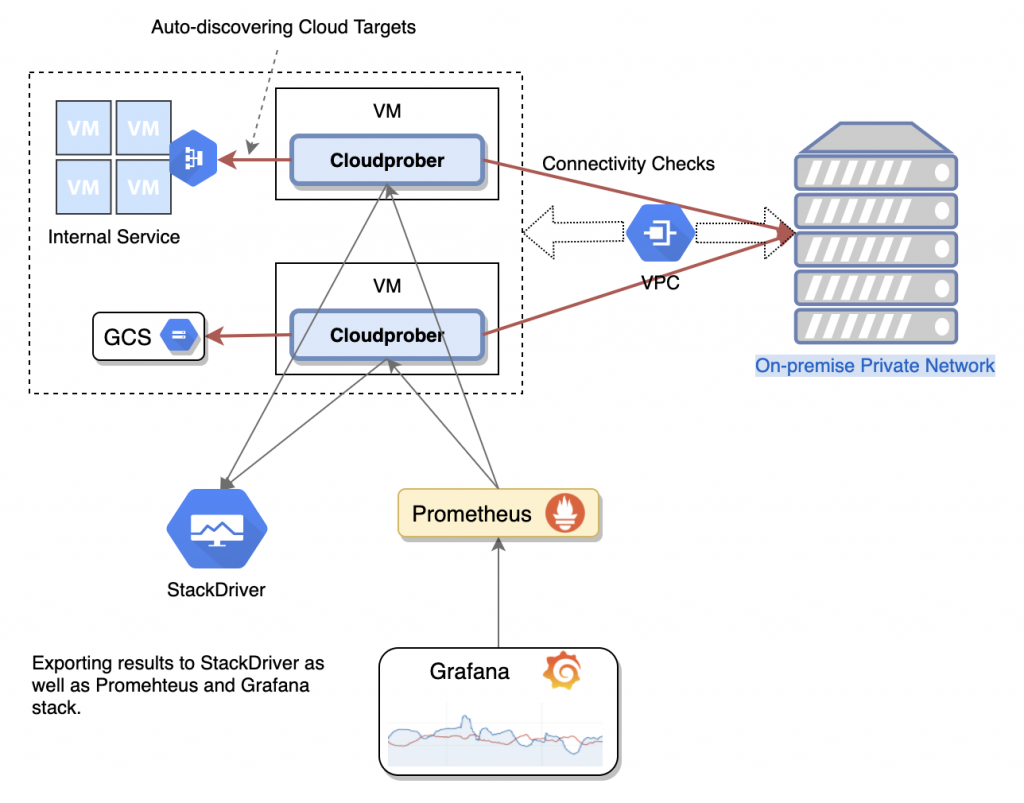
Como es un software basado en la nube, Cloudprober tiene soporte para el descubrimiento automático de objetivos. Se considera una de las características más críticas en los entornos dinámicos de hoy, ya que con ella, Cloudprober puede tocar datos de Kubernetes, Google Cloud Engine, AWS EC2, descubrimiento de archivos y más. Si eso no es suficiente, también tiene un servicio de descubrimiento interno, para que puedas integrar otros descubrimientos en tu infraestructura.
La idea central detrás del descubrimiento de objetivos de Clouprober es utilizar una fuente independiente para aclarar los objetivos que se supone deben ser monitoreados. Puede encontrar más información sobre las características destacadas del descubrimiento de objetivos de Cloudprober aquí.
Razones por las que Hostinger elige Cloudprober
En octubre de 2020, Hostinger estaba buscando un sistema de monitoreo externo para recopilar estadísticas de tiempo de actividad y velocidad de todos los sitios web de los usuarios. Consul (sitio web Blackbox cónsul) fue considerado como una de las principales alternativas para monitorear sitios. Sin embargo, Cloudprober parecía una opción liviana y prometedora que se integraba con Stackdriver, lo que le permitía almacenar registros fácilmente, no tenía restricciones de rendimiento y el equipo de datos podía acceder a ella sin requisitos adicionales.
Se han distinguido numerosos factores que explican por qué hemos elegido Cloudprober como alternativa preferida:
- Sin cabeza y ligero. La mayoría de las alternativas que hemos analizado tenían una solución completa con respecto al problema personalizado que intentan resolver: interfaz web, gestión de usuarios, gráficos personalizados, solución de base de datos/respaldo forzado, etc. Cloudprober solo hace una cosa: lanza y mide sondas. El flujo de trabajo está diseñado para ser simple y liviano para mantener bajo el uso de recursos. La implementación es solo un binario vinculado estáticamente (gracias a Golang).
- Composible. En este software de monitoreo se incluyen ventajosas herramientas integradas, sin embargo, se pueden ajustar configuraciones adicionales para hacer más.
- Extensible. La naturaleza extensible de Cloudprober permite a los usuarios agregar funciones a la herramienta si es necesario para adaptarse mejor a sus necesidades individuales. Además, se encuentra disponible una amplia documentación de soporte y una comunidad de usuarios.
- Vivo y mantenible. Antes de comprometerse con una tecnología, es aconsejable determinar si sus proyectos de Github aún están activos. Otro factor es determinar qué tan orientado a la comunidad está: problema y recuento de relaciones públicas, contribuyentes externos y actividad en general. Cloudprober pasó todos estos.
- Soporta todos los ecosistemas modernos. Cloudprober, como su nombre sugiere, fue diseñado para aplicaciones nativas en la nube desde el primer día. Se puede ejecutar como un contenedor (k8s), es compatible con la mayoría de los proveedores de nube pública para el descubrimiento de metadatos y objetivos, y es fácilmente integrable con herramientas modernas como Prometheus y Grafana. IPv6 tampoco es un problema para Coudprober.
Prueba para verificar si funciona para Hostinger
Las pruebas de Cloudprober fueron un proceso continuo en Hostinger. Para decidir si Cloudprober se ajusta a nuestras necesidades, verificamos la fidelidad de la métrica y los posibles escenarios de instalación/configuración para nuestra escala.
Intentamos cambiar el código de Cloudprober para agregar un control de concurrencia básico. Se intentaron diferentes patrones para mantener una carga moderada durante la medición de latencia: una concurrencia de 5+5 (HTTP + HTTPS). En servidores muy cargados, tomó aproximadamente 30 minutos rastrear alrededor de 3900 sitios HTTPS y aproximadamente 70 minutos para hacer lo mismo con alrededor de 7100 sitios HTTP.
El principal desafío que reconocimos fue la extensión de la sonda: Cloudprober espera un intervalo de verificación configurado e inicia todas las sondas al mismo tiempo. No lo vimos como un gran problema para Cloudprober en sí, ya que Consul, Prometheus y Blackbox Exporter comparten la misma función, pero esto puede tener un impacto en todo el servidor de hosting.
Más tarde, Cloudprober se lanzó en aproximadamente 1,8 millones de sitios, y descubrimos que una instancia de GCP con 8 núcleos y 32GiB o RAM puede manejarlo bien (60% de CPU inactiva).
Cómo aplicamos Cloudprober en Hostinger
Aquí en Hostinger, las métricas HTTP se envían a PostgreSQL (técnicamente, CloudSQL en GCP). Se utiliza el filtrado de métricas y las métricas internas de Cloudprober se exportan al aparejo de Prometheus. Para verificar si los sitios están realmente alojados con nosotros, enviamos un encabezado específico a cada sitio y esperamos otra respuesta de encabezado.
Salida métrica (Superficiales)
Inicialmente, pensamos que usaríamos un aparejo Prometheus. Sin embargo, toda la métrica recopilada tenía un tamaño de alrededor de 1 GB. Esto fue demasiado para nuestro sistema Prometheus + M3DB. Si bien es posible hacerlo funcionar, no vale la pena. Por lo tanto, decidimos seguir adelante con PostgreSQL. También evaluamos Stackdriver, pero PostgreSQL se ajustaba mejor a nuestras herramientas y propósitos.
De forma predeterminada, el aparejador de Cloudprober PostgreSQL espera este tipo de tabla:
CREATE TABLE metrics (
time TIMESTAMP WITH TIME ZONE,
metric_name text NOT NULL,
value DOUBLE PRECISION,
labels jsonb,
PRIMARY KEY (time, metric_name, labels)
);Hay algunos inconvenientes con este tipo de almacenamiento:
- Todas las etiquetas se colocan en el tipo jsonb.
- El tipo jsonb no es compatible con índices ni es fácil de consultar.
- Se almacenan más datos de los que necesitamos.
- Todos los datos se colocan en una gran tabla que no es fácil de mantener.
- Todos los datos almacenados como cadenas que ocupan mucho espacio de almacenamiento.
Al principio, destrozamos todos los insertos en una tabla. PostgreSQL (y muchos otros RDMS) presenta una técnica poderosa: triggers. Otra técnica notable se llama enumeraciones y permite almacenar datos “tipo cadena” de forma compacta (4 bytes por elemento). Al combinar estos dos con particiones, resolvimos todos los inconvenientes mencionados anteriormente.
Creamos dos tipos de datos personalizados:
CREATE TYPE http_scheme AS ENUM (
'http',
'https'
);CREATE TYPE metric_names AS ENUM (
'success',
'timeouts',
'latency',
'resp-code',
'total',
'validation_failure',
'external_ip',
'goroutines',
'hostname',
'uptime_msec',
'cpu_usage_msec',
'instance',
'instance_id',
'gc_time_msec',
'mem_stats_sys_bytes',
'instance_template',
'mallocs',
'frees',
'internal_ip',
'nic_0_ip',
'project',
'project_id',
'region',
'start_timestamp',
'version',
'machine_type',
'zone'
);Creamos la función de inserción de datos para el trigger:
CREATE OR REPLACE FUNCTION insert_fnc()
RETURNS trigger AS
$$
BEGIN
IF new.labels->>'dst' IS NULL THEN
RETURN NULL;
END IF;
new.scheme = new.labels->>'scheme';
new.vhost = rtrim(new.labels->>'dst', '.');
new.server = new.labels->>'server';
IF new.labels ? 'code' THEN
new.code = new.labels->>'code';
END IF;
new.labels = NULL;
RETURN new;
END;
$$
LANGUAGE 'plpgsql';Y la mesa principal:
CREATE TABLE metrics (
time TIMESTAMP WITH TIME ZONE,
metric_name metric_names NOT NULL,
scheme http_scheme NOT NULL,
vhost text NOT NULL,
server text NOT NULL,
value DOUBLE PRECISION,
labels jsonb,
code smallint
) PARTITION BY RANGE (time);Para la creación de particiones, podemos usar el siguiente script (crea particiones para los próximos 28 días y adjunta el disparador):
DO
$$
DECLARE
f record;
i interval := '1 day';
BEGIN
FOR f IN SELECT t as int_start, t+i as int_end, to_char(t, '"y"YYYY"m"MM"d"DD') as table_name
FROM generate_series (date_trunc('day', now() - interval '0 days'), now() + interval '28 days' , i) t
LOOP
RAISE notice 'table: % (from % to % [interval: %])', f.table_name, f.int_start, f.int_end, i;
EXECUTE 'CREATE TABLE IF NOT EXISTS m_' || f.table_name || ' PARTITION OF m FOR VALUES FROM (''' || f.int_start || ''') TO (''' || f.int_end || ''')';
EXECUTE 'CREATE TRIGGER m_' || f.table_name || '_ins BEFORE INSERT ON m_' || f.table_name || ' FOR EACH ROW EXECUTE FUNCTION insert_fnc()';
END LOOP;
END;
$$
LANGUAGE 'plpgsql';
Actualmente estamos en el proceso de realizar un monitoreo de host automáticamente tomando todos los hosts y la información del sitio web del Cónsul y usando la plantilla de cónsul para generar la configuración dinámica.
Particionamos los datos por día para la gestión de motivos y las operaciones sin bloqueo. También usamos desencadenadores y enumeraciones de PostgreSQL para filtrar, reescribir y eliminar jsonb filas para ahorrar espacio de almacenamiento (ahorros de hasta 10 veces) y acelerar las cosas. El equipo de datos importa esos datos de PostgreSQL a BigQuery y utiliza la manipulación o modificación de datos para satisfacer nuestras necesidades.
¿Cómo se vería la configuración real? Los datos dinámicos de la plantilla de cónsul se ven en la ruta del archivo, y Cloudprober volverá a leer este archivo en 600 segundos, por lo que se filtrará un archivo con todos los objetivos que tienen etiquetas para la sonda. Además, usamos “allow_metrics_with_label” para exponer diferentes tipos de métricas a diferentes superficies. Prometheus para el propio Cloudprober y PostgreSQL para sondeos. Para ahorrar ancho de banda de la red, usamos el método HTTP HEAD. No todos nuestros clientes tienen certificados TLS actualizados, por lo que debemos omitir las verificaciones de validez para ellos.
Cloudprober.cfg:
disable_jitter: true
probe {
name: "server1.hostinger.com-HTTP"
type: HTTP
targets {
rds_targets {
resource_path: "file:///tmp/targets.textpb"
filter {
key: "labels.probe",
value: "server1.hostinger.com-HTTP"
}
}
}
http_probe {
protocol: HTTP
port: 80
resolve_first: false
relative_url: "/"
method: HEAD
interval_between_targets_msec: 1000
tls_config {
disable_cert_validation: true
}
headers: {
name: "x-some-request-header"
value: "request-value"
}
}
additional_label {
key: "server"
value: "server1.hostinger.com"
}
additional_label {
key: "scheme"
value: "http"
}
interval_msec: 57600000
timeout_msec: 10000
validator {
name: "challenge-is-valid"
http_validator {
success_header: {
name: "x-some-response-header"
value: "header-value"
}
}
}
}
surfacer {
type: PROMETHEUS
prometheus_surfacer {
metrics_buffer_size: 100000
metrics_prefix: "cloudprober_"
}
allow_metrics_with_label {
key: "ptype",
value: "sysvars",
}
}
surfacer {
type: POSTGRES
postgres_surfacer {
connection_string: "postgresql://example:password@localhost/cloudprober?sslmode=disable"
metrics_table_name: "metrics"
metrics_buffer_size: 120000
}
allow_metrics_with_label {
key: "ptype",
value: "http",
}
}
rds_server {
provider {
file_config {
file_path: "/tmp/targets.textpb"
re_eval_sec: 600
}
}
}Ejemplo de /tmp/targets.textpb:
resource {
name: "hostinger.com."
labels {
key: "probe"
value: "server1.hostinger.com-HTTP"
}
}Solo tenemos una solicitud pendiente para satisfacer nuestras necesidades de usar Cloudprober correctamente, y Cloudprober se ejecuta en una sola instancia de 8x 2.20GHz y 32 GiB de RAM.
Fuentes de mayor interés
¿Te interesa probarlo y explorar las posibilidades de Cloudprober? Recomendamos consultar los siguientes sitios:
- https://cloudprober.org/getting-started/
- https://opensource.googleblog.com/2018/03/cloudprober-open-source-black-box.html
- https://medium.com/dm03514-tech-blog/sre-availability-probing-101-using-googles-cloudprober-8c191173923c
Más
- https://github.com/google/cloudprober/commit/3d5080b5dd0ee6a23395e6cf42a24c3e10557c2d
- https://github.com/google/cloudprober/commit/9f817036c98755d1f8da12b48b0ba00dbf331380
- https://github.com/google/cloudprober/commit/a1da1cd837b40598b3d9869b5ff2d8871ae38ea2
- https://github.com/google/cloudprober/commit/9674ae27076360098bc178330cc05191cb17ee89
- https://github.com/google/cloudprober/commit/0618ca6fe240a579400b153982fb383dc2df4dd6
- https://github.com/google/cloudprober/commit/a173510c80b854923366278d93fbc079c406e1fb
- https://github.com/google/cloudprober/commit/5aef6ad1aea957a01f6c690edde70a63136b3a6b
- https://github.com/google/cloudprober/commit/adab69a51b5059acd85e1f1940d7a3fc8a4b759b
- https://github.com/google/cloudprober/commit/684c9ce87416813cc523f07b7f9fb9a84abfc81e

Carlos es un profesional del marketing digital, eCommerce y de los constructores de sitios web. Ama ayudar a crecer a empresas en línea a través de sus tips. En su tiempo libre, seguramente está cantando o practicando artes marciales.